Aktuelles
DNB-Forschungsprojekt "Zeitenwende im Wortfeld"
Die Deutsche Nationalbibliothek hat unseren Projektantrag "Zeitenwende im Wortfeld" angenommen - damit werden wir voraussichtlich in der zweiten Jahreshälfte starten.
Im Rahmen des Projekts soll untersucht werden, ob und in welcher Form sich semantischer Bedeutungswandel und mithin gesellschaftlicher Wertewandel im Wortfeld Militär/Verteidigung als Folge der aktuellen geopolitischen Krisenlage sprachlich objektiv belegen und quantitativ erfassen lassen. Die Analyse nutzt KI-basierte Verfahren zur semantischen Modellierung, insbesondere sogenannte diachrone semantische Embeddings, die es erlauben, zeitliche Veränderungen in Bedeutungen und Konnotationen von Begriffen innerhalb des Wortfeldes Militär in der deutschen Tagespresse zu messen. Der erwartete Gewinn des Projekts besteht in einer linguistischen Bestandsaufnahme und datengetriebenen Ergänzung qualitativer, diskursanalytischer Analysen zu der sich aktuell vollziehenden “Zeitenwende“.
Eine vollständige Projektskizze kann hier heruntergeladen werden.
Siehe auch: Thema "Vektordatenbank & Embeddings" sowie Thema "Visualisierungen"
DWDS-Datentransformation
Das DWDS-Team hat uns freundlicherweise einige vollständige Testdatensätze zur Verfügung gestellt. Diese Daten sind mittels eines Python-Transformers (ähnlich XSLT) vollständig in unser Datenbankformat konvertiert worden und können über lexoterm.de abgerufen werden. Weitere Datenintegrationen aus anderen Wörterbüchern werden folgen.
LexFCS-Endpoint
Bereits im Winter 2025 haben wir der Sächsischen Akademie und dem Team um LexFCS zugesagt, eine Schnittstelle zwischen BDO und LexFCS bereitzustellen. Nun ist sie fertig, und der BDO-Datenbestand mit den Wörterbüchern zum bayerischen, fränkischen und schwäbischen Dialekt kann auch über LexFCS bzw. Text+ abgerufen werden.
Lexoterm Release I
Alle Daten und Werkzeuge des Pilotprojekts werden auf dem Portal lexoterm.de veröffentlicht. Der erste Meilenstein ist weitestgehend abgeschlossen.
Hinweis: Aktuell ist der Zugang noch zugriffsbeschränkt - für eine Vorschau gerne Kontakt aufnehmen!
Features:
- Wörterbuchsuche ist über eine Vielzahl an Wörterbüchern möglich; aktuell sind BWB WBF und DIBS integriert. Die Suche ist flexibel erweiterbar und bietet unter anderem volle Regex-Unterstützung.
- Die Integration weiterer Wörterbücher zu Testzwecken ist gegenwärtig in Vorbereitung.
- Eine Werkzeug-Übersicht bietet Zugriff auf verschiedene selbstentwickelte Tools sowie solche von Partnern und Drittanbietern.
- Für den schnellen Zugriff wurde ein eigenes Datenformat - basierend auf JSON - entwickelt. Aktuell nutzt Lexoterm MongoDB als Datenbank. Das Datenformat ist sowohl darauf ausgelegt, über standardisierte Transformationen Daten aus verschiedensten Wörterbüchern aufzunehmen, wie auch diese wiederum in TEI Lex-0 bereitzustellen.
Siehe auch: Thema "Lexikographie-Portal"
Werkzeug: Morphologische Segmentierung
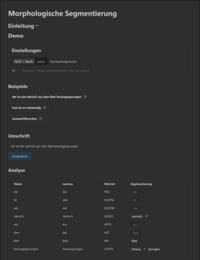
Dieses Werkzeug segmentiert Wörter und Sätze morphologisch - hilfreich, um Stammformen für die Vorbereitung eines Wörterbucheintrages zu generieren.
Features
- Vorverarbeitung mit NLTK und HanTa oder wahlweise spaCy:
- Tokenisierung
- Stoppwort-Erkennung
- Lemmatisierung
- Wortarten-Annotation
- Nur mit spaCy: Syntaktische Analyse (zur Rekonstruktion von trennbaren Verben)
- Morphologische Analyse mit SMOR
Siehe auch: Thema "KI-gestützte Workflows"
Werkzeug: LT Wörterbuch-Konsistenzprüfung
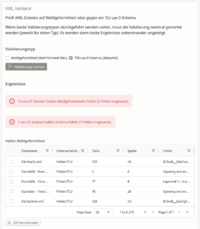
Eine erste Version unseres Tools zur Wörterbuchkonsistenzprüfung ist online:
https://dictconsistency.tools.lexoterm.de/
Dieses Werkzeug bietet verschiedene Möglichkeiten zur Konsistenzprüfung von Wörterbüchern auf XML-Basis. Es funktioniert mit beliebigen XML-Schemata, aber am besten mit TEI-Lex 0.
Features:
- Upload von Dateien aus einem lokalen Verzeichnis, oder per ZIP.
- XML/TL0 Validator: Prüfung auf XML-Wohlgeformtheit und TEI-Lex 0 Konformität
- Strukturanalyse: Die Struktur bereitgestellter XML-Dateien wird analysiert, dargestellt und durchsuchbar gemacht.
- Tag- und Pfadsuche: Suche nach bestimmten Tags oder Pfaden im XML-Baum, inklusive Wildcards
- Inhalt / Leere Tags: Suche nach Textinhalten, leeren Tags und Umbrüchen
- Einmaligkeit: Prüft, ob Tags oder Attribute mehrfach vorkommen
- Verschachtelung: Prüft auf verschachtelte XML-Elemente
- LLM-Anfrage: Einzelne oder mehrere XML-Dateien können an ein lokales oder Cloud-LLM gesendet werden. Per Chat-Funktion können Fragen gestellt und Analysen vorgenommen werden.
Siehe auch: Thema "Konsistenzprüfung"
Werkzeug: LT Sachgruppen-Vorhersage
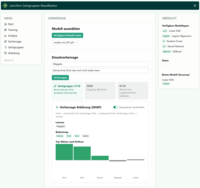
Inspiriert von einem Tool unserer Kolleg*innen aus der Abteilung Digital Humanities, das Sachgruppen mittels LLM Prompting vorhersagt, haben wir ein Tool getestet, das auf klassische Machine-Learning-Verfahren (ohne LLMs) setzt.
https://sgpredict.tools.lexoterm.de/
Als Basis werden existierender Klassifikationen aus den Wörterbüchern WBF und DIBS als Trainingsdaten verwendet. Diese nutzen die klassische Taxonomie nach Hallig-Wartburg.
Features
- Training: Neue Modelle können unter Verwendung von Linear SVM, Logistic Regression, Random Forest, XGBoost und Neural Networks trainiert werden. Dabei stehen zahlreiche Parameter und Hyperparameter zur Konfiguration zur Verfügung.
- Analyse: Übersicht aller trainierten Modelle mit Accuracy, Parametern und Trainingszeiten sowie detaillierten Klassifikationsreports
- Vorhersage: Klassifizierung/Vorhersage für neue Lemmata (einzeln oder im Batch)
- Sachgruppen: Auswertung der Trainings- und Prognosedaten pro Sachgruppe. Erlaubt auch Erkenntnisse hinsichtlich der lexikographischen Arbeit
Siehe auch: Thema "KI-gestützte Workflows"
Werkzeug: LT Visueller Wortauschluss
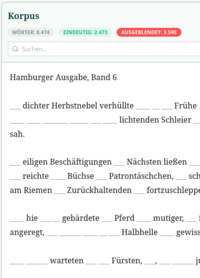
Für die meisten Aufgaben im Bereich Tokenisierung und Embedding werden Stopwords verwendet, und üblicherweise lädt man eine Standardliste als Teil einer Programmbibliothek. Für den seltenen Fall, dass individualisierte Stopword-Listen benötigt werden, etwa im Bereich der Dialekte oder historischen Sprachstufen, hilft dieses Tool:
https://stopandgraph.tools.lexoterm.de/
Features:
- Kann hinterlegte Texte oder vom Nutzer hochgeladene Texte verarbeiten.
- Stopwords können durch Klicken im Text bzw. in einer Wordcloud oder Liste entfernt oder hinzugefügt werden.
- Zusätzlich lassen sich mittels Named Entity Recognition und Part of Speech-Erkennung ganze Wortgruppen (z.B. Namen, Orte, Substantive, Verben) ein- oder ausschließen. (noch in Entwicklung)
- Die Stopword-Liste und der bearbeitete Text können heruntergeladen werden.
- Der erzeugte Text kann im nächsten Schritt als Graph visualisiert werden; dabei lässt sich der Graph über viele Parameter präzise steuern.
Siehe auch: Themen "Wissensgraphen" und "Visualisierungen"
Werkzeug: LT Wörterbuch-Graph
Dieses Tool ist entstanden als visuelle Spielerei - aber die Graph-Analyse von Wörterbuchdaten hat ernsthafte Anwendungsfälle. Dementsprechend soll das Tool kontinuierlich ausgebaut werden.
https://dictgraph.tools.lexoterm.de/
Gegenwärtig erstellt es Graphen aus XML TEI Lex-0-Daten, basierend auf den Verweisattributen zu Etymologie, Wortfamilie, Ableitungen und Komposita.
Features:
- Upload von XML-Files als Datei
- Automatische Berechnung der Knoten und Kanten
- Graph-Generierung
- Filter- und Suche im Graph
- Farb-Themes
- Grafik- und Datenexport
Siehe auch: Themen "Wissensgraphen" und "Visualisierungen"